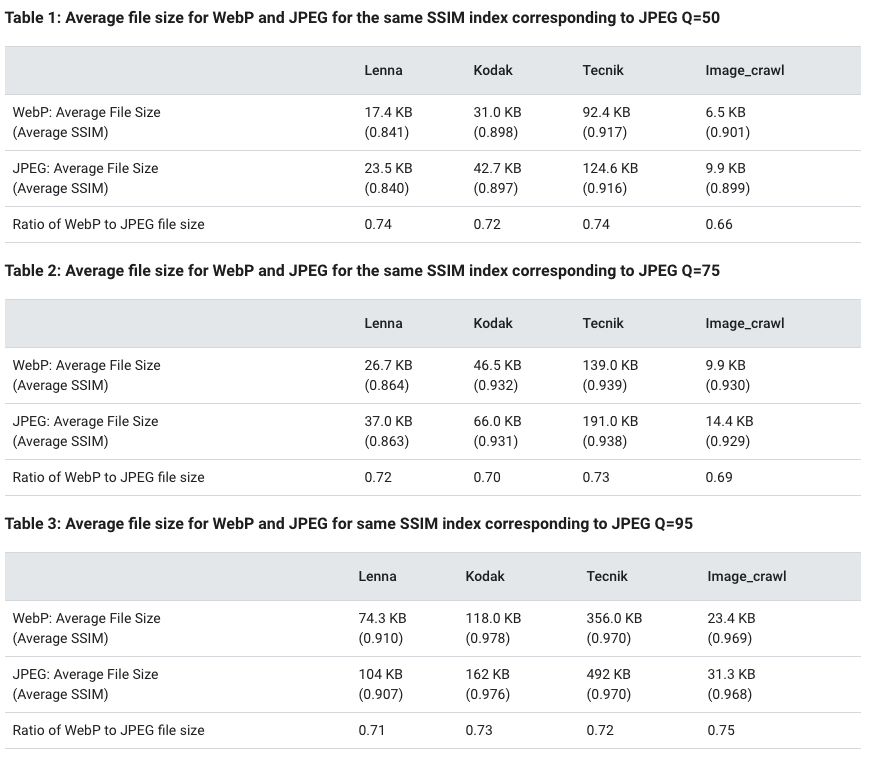
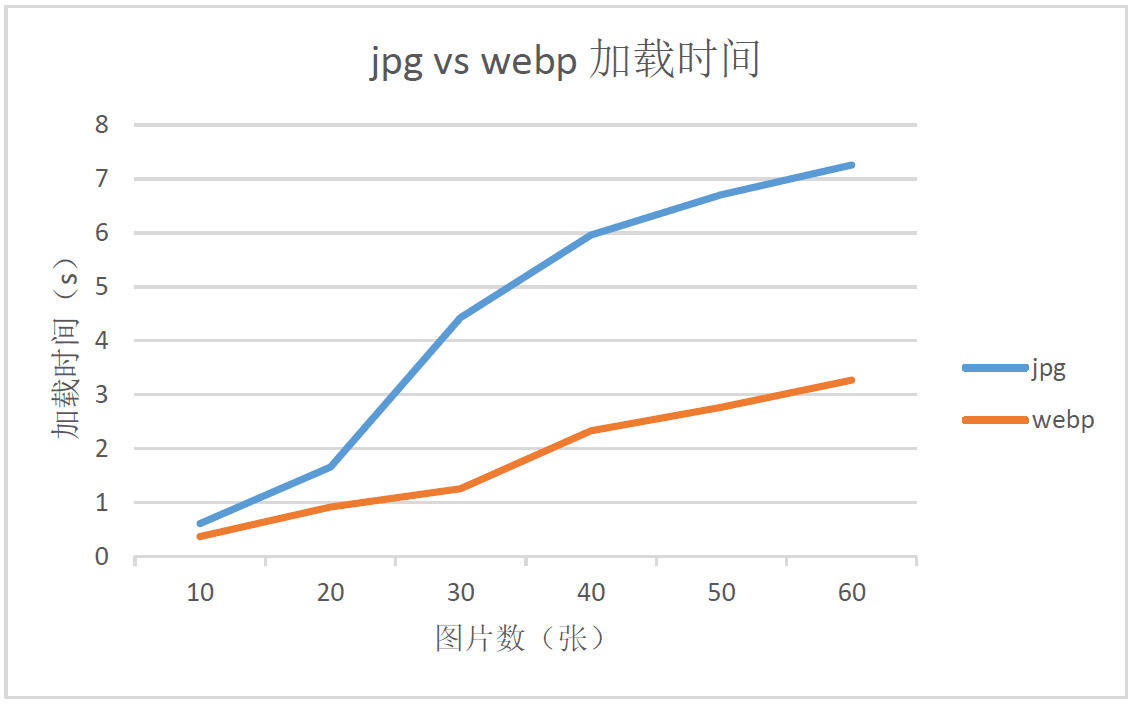
WebP is a modern image format that provides superior lossless and lossy compression for images on the web. Using WebP, webmasters and web developers can create smaller, richer images that make the web faster.
在 Android 中,TTS全称叫做 Text to Speech,从字面就能理解它解决的问题是什么,把文本转为语音服务,意思就是你输入一段文本信息,然后Android 系统可以把这段文字播报出来。这种应用场景目前比较多是在各种语音助手APP上,很多手机系统集成商内部都有内置文本转语音服务,可以读当前页面上的文本信息。同样,在一些阅读类APP上我们也能看到相关服务,打开微信读书,里面就直接可以把当前页面直接用语音方式播放出来,特别适合哪种不方便拿着手机屏幕阅读的场景。
privatevoidinit(){ mTTS = new TextToSpeech(this.getApplicationContext(),this); mXKAudioPolicyManager = XKAudioPolicyManager.getInstance(this.getApplication()); mParams = new HashMap(); mParams.put(TextToSpeech.Engine.KEY_PARAM_STREAM, "3"); //设置播放类型(音频流类型) }
@Override publicvoidonInit(int status){ if (status == TextToSpeech.SUCCESS) { int result = mTTS.setLanguage(Locale.ENGLISH); if (result == TextToSpeech.LANG_MISSING_DATA || result == TextToSpeech.LANG_NOT_SUPPORTED) { Toast.makeText(this, "数据丢失或不支持", Toast.LENGTH_SHORT).show(); } } }
@Override publicvoidonClick(View v){ int id = v.getId(); switch (id){ case R.id.btn_tts1: TtsPlay1(); break; case R.id.btn_tts2: TtsPlay2(); break; case R.id.btn_second: TtsSecond(); break; case R.id.btn_cycle: TtsCycle(); break; default: break; } }
privatevoidTtsPlay1(){ if (mTTS != null && !mTTS.isSpeaking() && mXKAudioPolicyManager.requestAudioSource()) { //mTTS.setOnUtteranceProgressListener(new ttsPlayOne()); String text1 = mTestEt1.getText().toString(); Log.d(TAG, "TtsPlay1-----------播放文本内容:" + text1); //朗读,注意这里三个参数的added in API level 4 四个参数的added in API level 21 mTTS.speak(text1, TextToSpeech.QUEUE_FLUSH, mParams); } }
privatevoidTtsPlay2(){ if (mTTS != null && !mTTS.isSpeaking() && mXKAudioPolicyManager.requestAudioSource()) { //mTTS.setOnUtteranceProgressListener(new ttsPlaySecond()); String text2 = mTestEt2.getText().toString(); Log.d(TAG, "TtsPlay2-----------播放文本内容:" + text2); // 设置音调,值越大声音越尖(女生),值越小则变成男声,1.0是常规 mTTS.setPitch(0.8f); //设定语速 ,默认1.0正常语速 mTTS.setSpeechRate(1f); //朗读,注意这里三个参数的added in API level 4 四个参数的added in API level 21 mTTS.speak(text2, TextToSpeech.QUEUE_FLUSH, mParams); } }
privatevoidTtsSecond(){ Intent intent = new Intent(TtsMainActivity.this,TtsSecondAcitivity.class); startActivity(intent); }
privatevoidTtsCycle(){ long millis1 = System.currentTimeMillis();
for (int i = 0; i < THREADNUM; i++) { Thread tempThread = new Thread(new MyRunnable(i, THREADNUM)); tempThread.setName("线程" + i); tempThread.start(); }
privateintinitTts(){ // Step 1: Try connecting to the engine that was requested. if (mRequestedEngine != null) { if (mEnginesHelper.isEngineInstalled(mRequestedEngine)) { if (connectToEngine(mRequestedEngine)) { mCurrentEngine = mRequestedEngine; return SUCCESS; } elseif (!mUseFallback) { mCurrentEngine = null; dispatchOnInit(ERROR); return ERROR; } } elseif (!mUseFallback) { Log.i(TAG, "Requested engine not installed: " + mRequestedEngine); mCurrentEngine = null; dispatchOnInit(ERROR); return ERROR; } }
// Step 2: Try connecting to the user's default engine. final String defaultEngine = getDefaultEngine(); if (defaultEngine != null && !defaultEngine.equals(mRequestedEngine)) { if (connectToEngine(defaultEngine)) { mCurrentEngine = defaultEngine; return SUCCESS; } }
// Step 3: Try connecting to the highest ranked engine in the // system. final String highestRanked = mEnginesHelper.getHighestRankedEngineName(); if (highestRanked != null && !highestRanked.equals(mRequestedEngine) && !highestRanked.equals(defaultEngine)) { if (connectToEngine(highestRanked)) { mCurrentEngine = highestRanked; return SUCCESS; } }
// NOTE: The API currently does not allow the caller to query whether // they are actually connected to any engine. This might fail for various // reasons like if the user disables all her TTS engines.
// Load the engineConfig from the plugin if it has any special configuration // to be loaded. By convention, if an engine wants the TTS framework to pass // in any configuration, it must put it into its content provider which has the URI: // content://<packageName>.providers.SettingsProvider // That content provider must provide a Cursor which returns the String that // is to be passed back to the native .so file for the plugin when getString(0) is // called on it. // Note that the TTS framework does not care what this String data is: it is something // that comes from the engine plugin and is consumed only by the engine plugin itself. String engineConfig = ""; Cursor c = getContentResolver().query(Uri.parse("content://" + getPackageName() + ".providers.SettingsProvider"), null, null, null, null); if (c != null){ c.moveToFirst(); engineConfig = c.getString(0); c.close(); } mNativeSynth = new SynthProxy(soFilename, engineConfig);
// mNativeSynth is used by TextToSpeechService#onCreate so it must be set prior // to that call. // getContentResolver() is also moved prior to super.onCreate(), and it works // because the super method don't sets a field or value that affects getContentResolver(); // (including the content resolver itself). super.onCreate(); }
/** init * Allocates Pico memory block and initializes the Pico system. * synthDoneCBPtr - Pointer to callback function which will receive generated samples * config - the engine configuration parameters, here only contains the non-system path * for the lingware location * return tts_result */ tts_result TtsEngine::init( synthDoneCB_t synthDoneCBPtr, constchar *config ) { if (synthDoneCBPtr == NULL) { ALOGE("Callback pointer is NULL"); return TTS_FAILURE; }
picoMemArea = malloc( PICO_MEM_SIZE ); if (!picoMemArea) { ALOGE("Failed to allocate memory for Pico system"); return TTS_FAILURE; }
pico_Status ret = pico_initialize( picoMemArea, PICO_MEM_SIZE, &picoSystem ); if (PICO_OK != ret) { ALOGE("Failed to initialize Pico system"); free( picoMemArea ); picoMemArea = NULL; return TTS_FAILURE; }
picoSynthDoneCBPtr = synthDoneCBPtr;
picoCurrentLangIndex = -1;
// was the initialization given an alternative path for the lingware location? if ((config != NULL) && (strlen(config) > 0)) { pico_alt_lingware_path = (char*)malloc(strlen(config)); strcpy((char*)pico_alt_lingware_path, config); ALOGV("Alternative lingware path %s", pico_alt_lingware_path); } else { pico_alt_lingware_path = (char*)malloc(strlen(PICO_LINGWARE_PATH) + 1); strcpy((char*)pico_alt_lingware_path, PICO_LINGWARE_PATH); ALOGV("Using predefined lingware path %s", pico_alt_lingware_path); }
/** * Adds a speech item to the queue. * * Called on a service binder thread. */ publicintenqueueSpeechItem(int queueMode, final SpeechItem speechItem){ UtteranceProgressDispatcher utterenceProgress = null; if (speechItem instanceof UtteranceProgressDispatcher) { utterenceProgress = (UtteranceProgressDispatcher) speechItem; }
if (!speechItem.isValid()) { if (utterenceProgress != null) { utterenceProgress.dispatchOnError( TextToSpeech.ERROR_INVALID_REQUEST); } return TextToSpeech.ERROR; }
// The obj is used to remove all callbacks from the given app in // stopForApp(String). // // Note that this string is interned, so the == comparison works. msg.obj = speechItem.getCallerIdentity();
if (sendMessage(msg)) { return TextToSpeech.SUCCESS; } else { Log.w(TAG, "SynthThread has quit"); if (utterenceProgress != null) { utterenceProgress.dispatchOnError(TextToSpeech.ERROR_SERVICE); } return TextToSpeech.ERROR; } }
主要是看 speechItem.play()方法,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/** * Plays the speech item. Blocks until playback is finished. * Must not be called more than once. * * Only called on the synthesis thread. */ publicvoidplay(){ synchronized (this) { if (mStarted) { thrownew IllegalStateException("play() called twice"); } mStarted = true; } playImpl(); }
@Override protectedvoidplayImpl(){ AbstractSynthesisCallback synthesisCallback; mEventLogger.onRequestProcessingStart(); synchronized (this) { // stop() might have been called before we enter this // synchronized block. if (isStopped()) { return; } mSynthesisCallback = createSynthesisCallback(); synthesisCallback = mSynthesisCallback; }
// Fix for case where client called .start() & .error(), but did not called .done() if (synthesisCallback.hasStarted() && !synthesisCallback.hasFinished()) { synthesisCallback.done(); } }
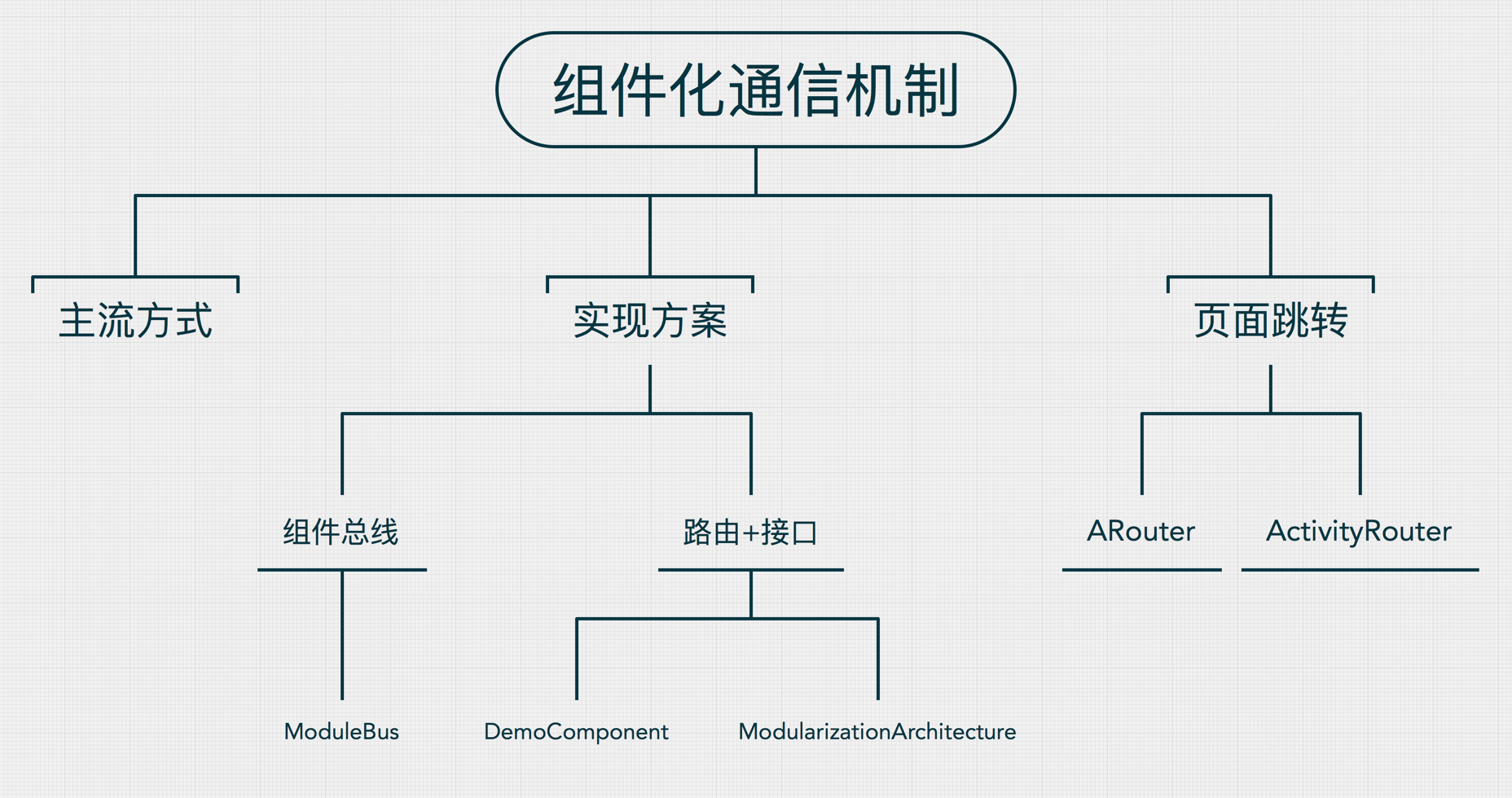
接口+路由实现方式则相对容易理解点,我之前实践的一个项目就是通过这种方式实现的。具体地址如下:DemoComponent 实现思路是专门抽取一个LibModule作为路由服务,每个组件声明自己提供的服务 Service API,这些 Service 都是一些接口,组件负责将这些 Service 实现并注册到一个统一的路由 Router 中去,如果要使用某个组件的功能,只需要向Router 请求这个 Service 的实现,具体的实现细节我们全然不关心,只要能返回我们需要的结果就可以了。
比如定义两个路由地址,一个登陆组件,一个设置组件,核心代码:
1 2 3 4 5 6 7 8 9
publicclassRouterPath{
//注意路由的命名,路径第一个开头需要不一致,保证唯一性 //Login Service publicstaticfinal String ROUTER_PATH_TO_LOGIN_SERVICE = "/login/service";
//Setting Service publicstaticfinal String ROUTER_PATH_TO_SETTING_SERVICE = "/setting/service"; }
1,XSS 跨站攻击技术:主要是攻击者往网页里嵌入恶意脚本,或者通过改变 HTML 元素属性来实现攻击,主要原因在于开发者对用户的变量直接使用导致进入 HTML 中会被直接编译成 JS,通常的 GET 请求通过 URL 来传参,可以在 URL 中传入恶意脚本,从而获取信息,解决方法:特殊字符过滤。
2,SQL 注入攻击:主要是就是通过把 SQL 命令插入到 Web 表单 提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的 SQL 命令,比如 select * from test where username="wuxu" or 1=1,这样会使用户跳过密码直接登录,具体解决方案:
特殊字符过滤,不要用拼接字符串的方法来凑sql语句。
对 sql 语句进行预编译,比如 java 的 preparedstatement。
关闭错误信息,攻击者可能会通过不断的尝试来得到数据库的一些信息,所以关闭错误信息变得重要起来。
客户端对数据进行加密,使原来传进来的参数因为加密而被过滤掉。
控制数据库的权限,比如只能 select,不能 insert,防止攻击者通过 select * from test ;drop tables这种操作。
]]>
对于HTTP协议,想必大家都不陌生,那如果让你讲讲来源、用途、HTTPS协议区别,你能讲出所以然来吗,我目前就是因为讲不是很清楚,所以有必要做个总结。
Android组件化框架设计与实践http://cryallen.com/2018/02/05/2018-02-05-AndroidComponent/2018-02-05T14:47:50.000Z2020-12-30T04:12:03.382Z在目前移动互联网时代,每个 APP 就是流量入口,与过去 PC Web 浏览器时代不同的是,APP 的体验与迭代速度影响着用户的粘性,这同时也对从事移动开发人员提出更高要求,进而移动端框架也层出不穷。服务端与移动端对比
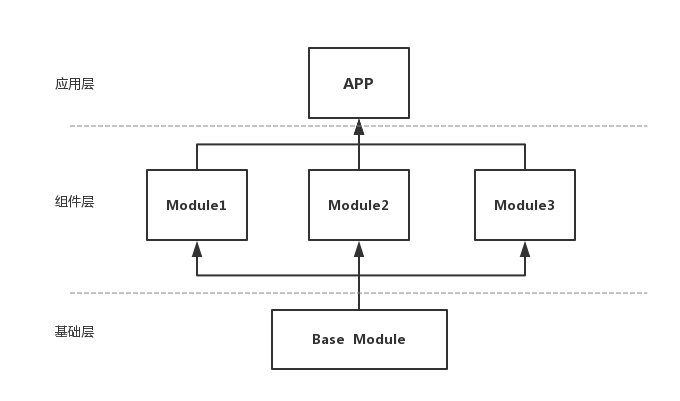
上图显示的是传统的服务端架构和客户端 App 架构对比。传统的服务端架构中最底下是一个 OS,一般是 Linux,最上面服务端的业务,而中间有非常多的层次可以在架构上,按照我们的意愿搭建中间的各个层次的衔接环节,使得架构具有足够的灵活性和扩展性。但是到了 App 就会面对一个完全不同的现状,App 的OS(Android或iOS)本质上并不是一个很瘦的像 Linux 这样的 OS,而是在 OS 上有一个很重的 App Framework,开发一个普通的客户端应用所要用到的绝大多数接口都在 Framework 里,而上面的业务也是一个非常复杂多样化的业务,最后会发现“架构”是在中间的一个非常尴尬的夹心层,因为会遇到很多在服务端架构中不需要面临的挑战。比如以下两点:
通过接口+实现的结构进行组件间的通信。每个组件声明自己提供的服务 Service API,这些 Service 都是一些接口,组件负责将这些 Service 实现并注册到一个统一的路由 Router 中去,如果要使用某个组件的功能,只需要向Router 请求这个 Service 的实现,具体的实现细节我们全然不关心,只要能返回我们需要的结果就可以了。在组件化架构设计图中 Common 组件就包含了路由服务组件,里面包括了每个组件的路由入口和跳转。
基于目前市场表现,我们都知道下一个风口是 AI,但是作为一个移动开发者如何在即将来临的 AI 时代吃口红利呢。我的回答是:致力于做一个终身学习者,追本溯源去探寻代码世界哪些不变的道,你又会说了,哪些是道呢,简单举例下,比如编程思想、常用的设计模式、设计原则、算法和数据结构、网络通信机制、操作系统、重构原则、架构思维等等。同时在目前发展情形下,也越来越趋向全栈工程师的路线,借用之前在网上看到一篇文章的图,想进阶全栈工程师之路看需要哪些技能,如下:
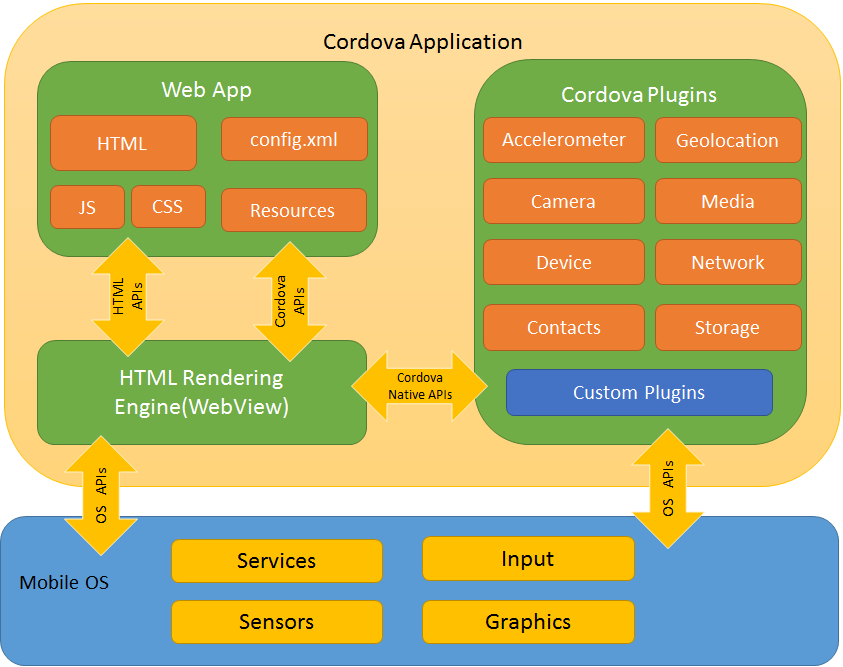
随着公司业务不断发展,移动开发项目越来越多,项目任务时间紧,我们内部开发流程是以项目为导向,有别于一般公司对产品不断迭代的做法,但移动端开发人员资源有限,需要在不同项目之间做业务场景切换开发,就会经常出现项目完成时间 Delay。面对这样的问题,我们该如何去解决呢?现在了解到的现状是每个业务组都有配备 Web 前端开发人员,那么是否能把涉及到业务模块分发给具体业务组 Web 前端开发人员去开发,剥离业务模块,我们移动端开发人员则专注于框架的开发或者手机端设备能力开发,比如可支持调用摄像头,监听网络状态变化,提供地理位置信息等等,有没有这样一套适合的解决方案呢,答案当然是有的。我们引入了可利用 Web 前端能力和移动端操作系统原生能力相结合开发模式,叫做 Hybrid 混合开发。
总的来说,单元测试不是集成测试,单元测试只是测试一个方法单元,不是测试一整个流程。集成测试是一种End To End的系统测试,测试相关模块集成在一起是否能够按照预期工作,一般都是接口或者功能层面的测试,可能会依赖很多系统因素,测试的代码逻辑一般比较复杂,运行时间会比较长,出错之后的修复成本高。单元测试则是开发者在集成测试之前就已经进行自测过,同时呢,进行单元测试之后,对于某个方法的执行路径组合进行了一一验证,它只关注三个目标:
// enable Cordova apps to be started in the background Bundle extras = getIntent().getExtras(); if (extras != null && extras.getBoolean("cdvStartInBackground", false)) { moveTaskToBack(true); }
// Set by <content src="index.html" /> in config.xml loadUrl(launchUrl); } }
privatestaticvoidexposeJsInterface(WebView webView, CordovaBridge bridge){ if ((Build.VERSION.SDK_INT < Build.VERSION_CODES.JELLY_BEAN_MR1)) { LOG.i(TAG, "Disabled addJavascriptInterface() bridge since Android version is old."); // Bug being that Java Strings do not get converted to JS strings automatically. // This isn't hard to work-around on the JS side, but it's easier to just // use the prompt bridge instead. return; } SystemExposedJsApi exposedJsApi = new SystemExposedJsApi(bridge); webView.addJavascriptInterface(exposedJsApi, "_cordovaNative"); }
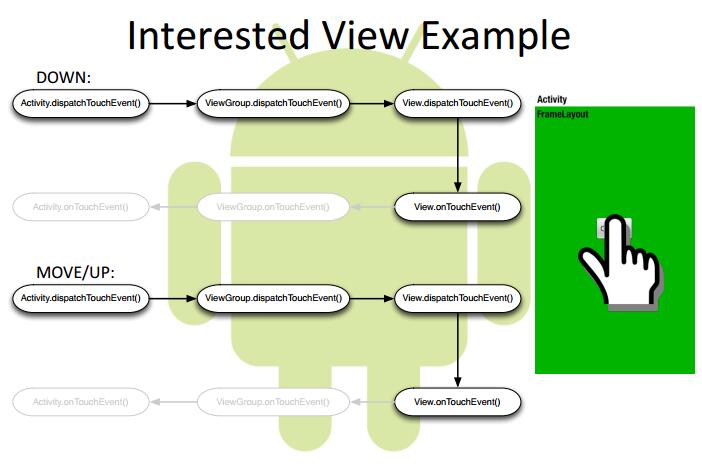
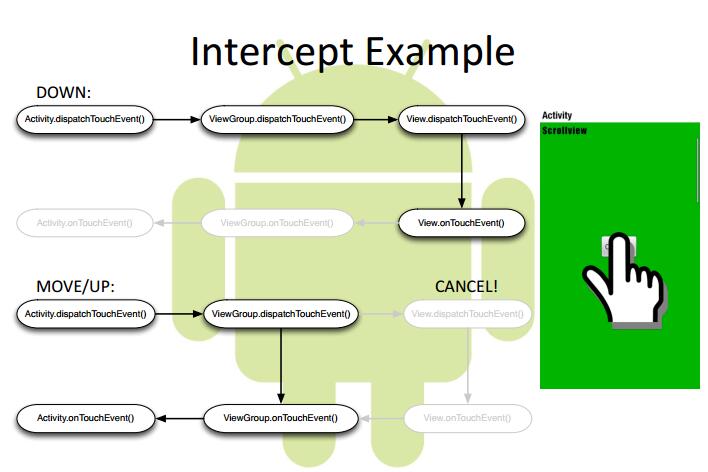
@Override publicbooleanonTouchEvent(MotionEvent event){ mVelocityTracker.addMovement(event); int x = (int) event.getX(); int y = (int) event.getY(); switch (event.getAction()) { case MotionEvent.ACTION_DOWN: { if (!mScroller.isFinished()) { mScroller.abortAnimation(); } break; } case MotionEvent.ACTION_MOVE: { int deltaX = x - mLastX; scrollBy(-deltaX, 0); break; } case MotionEvent.ACTION_UP: { int scrollX = getScrollX(); mVelocityTracker.computeCurrentVelocity(1000); float xVelocity = mVelocityTracker.getXVelocity(); if (Math.abs(xVelocity) >= 50) { mChildIndex = xVelocity > 0 ? mChildIndex - 1 : mChildIndex + 1; } else { mChildIndex = (scrollX + mChildWidth / 2) / mChildWidth; } mChildIndex = Math.max(0, Math.min(mChildIndex, mChildrenSize - 1)); int dx = mChildIndex * mChildWidth - scrollX; smoothScrollBy(dx, 0); mVelocityTracker.clear(); break; } default: break; }
mLastX = x; mLastY = y; returntrue; }
@Override protectedvoidonMeasure(int widthMeasureSpec, int heightMeasureSpec){ super.onMeasure(widthMeasureSpec, heightMeasureSpec); int measuredWidth = 0; int measuredHeight = 0; finalint childCount = getChildCount(); measureChildren(widthMeasureSpec, heightMeasureSpec);
int widthSpaceSize = MeasureSpec.getSize(widthMeasureSpec); int widthSpecMode = MeasureSpec.getMode(widthMeasureSpec); int heightSpaceSize = MeasureSpec.getSize(heightMeasureSpec); int heightSpecMode = MeasureSpec.getMode(heightMeasureSpec); if (childCount == 0) { setMeasuredDimension(0, 0); } elseif (heightSpecMode == MeasureSpec.AT_MOST) { final View childView = getChildAt(0); measuredHeight = childView.getMeasuredHeight(); setMeasuredDimension(widthSpaceSize, childView.getMeasuredHeight()); } elseif (widthSpecMode == MeasureSpec.AT_MOST) { final View childView = getChildAt(0); measuredWidth = childView.getMeasuredWidth() * childCount; setMeasuredDimension(measuredWidth, heightSpaceSize); } else { final View childView = getChildAt(0); measuredWidth = childView.getMeasuredWidth() * childCount; measuredHeight = childView.getMeasuredHeight(); setMeasuredDimension(measuredWidth, measuredHeight); } }
@Override protectedvoidonLayout(boolean changed, int l, int t, int r, int b){ int childLeft = 0; finalint childCount = getChildCount(); mChildrenSize = childCount;
for (int i = 0; i < childCount; i++) { final View childView = getChildAt(i); if (childView.getVisibility() != View.GONE) { finalint childWidth = childView.getMeasuredWidth(); mChildWidth = childWidth; childView.layout(childLeft, 0, childLeft + childWidth, childView.getMeasuredHeight()); childLeft += childWidth; } } }
@Override publicbooleandispatchTouchEvent(MotionEvent event){ int x = (int) event.getX(); int y = (int) event.getY();
switch (event.getAction()) { case MotionEvent.ACTION_DOWN: { mHorizontalScrollViewEx2.requestDisallowInterceptTouchEvent(true); break; } case MotionEvent.ACTION_MOVE: { int deltaX = x - mLastX; int deltaY = y - mLastY; if (父容器需要此类点击事件) { mHorizontalScrollViewEx2.requestDisallowInterceptTouchEvent(false); } break; } case MotionEvent.ACTION_UP: { break; } default: break; }
privatestaticfinalint CPU_COUNT = Runtime.getRuntime().availableProcessors(); // We want at least 2 threads and at most 4 threads in the core pool, // preferring to have 1 less than the CPU count to avoid saturating // the CPU with background work privatestaticfinalint CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4)); privatestaticfinalint MAXIMUM_POOL_SIZE = CPU_COUNT * 2 + 1; privatestaticfinalint KEEP_ALIVE_SECONDS = 30;
privatestaticfinal ThreadFactory sThreadFactory = new ThreadFactory() { privatefinal AtomicInteger mCount = new AtomicInteger(1);
/** * An {@link Executor} that executes tasks one at a time in serial * order. This serialization is global to a particular process. */ publicstaticfinal Executor SERIAL_EXECUTOR = new SerialExecutor();
/** * Indicates the current status of the task. Each status will be set only once * during the lifetime of a task. */ publicenum Status { /** * Indicates that the task has not been executed yet. */ PENDING, /** * Indicates that the task is running. */ RUNNING, /** * Indicates that {@link AsyncTask#onPostExecute} has finished. */ FINISHED, }
privatestatic Handler getHandler(){ synchronized (AsyncTask.class) { if (sHandler == null) { sHandler = new InternalHandler(); } return sHandler; } }
/** * Creates a new asynchronous task. This constructor must be invoked on the UI thread. */ publicAsyncTask(){ mWorker = new WorkerRunnable<Params, Result>() { public Result call()throws Exception { mTaskInvoked.set(true); Result result = null; try { Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND); //noinspection unchecked result = doInBackground(mParams); Binder.flushPendingCommands(); } catch (Throwable tr) { mCancelled.set(true); throw tr; } finally { postResult(result); } return result; } };
private Result postResult(Result result){ @SuppressWarnings("unchecked") Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT, new AsyncTaskResult<Result>(this, result)); message.sendToTarget(); return result; }
/** * Returns the current status of this task. * * @return The current status. */ publicfinal Status getStatus(){ return mStatus; }
/** * Override this method to perform a computation on a background thread. The * specified parameters are the parameters passed to {@link #execute} * by the caller of this task. * * This method can call {@link #publishProgress} to publish updates * on the UI thread. * * @param params The parameters of the task. * * @return A result, defined by the subclass of this task. * * @see #onPreExecute() * @see #onPostExecute * @see #publishProgress */ @WorkerThread protectedabstract Result doInBackground(Params... params);
/** * Runs on the UI thread before {@link #doInBackground}. * * @see #onPostExecute * @see #doInBackground */ @MainThread protectedvoidonPreExecute(){ }
/** * <p>Runs on the UI thread after {@link #doInBackground}. The * specified result is the value returned by {@link #doInBackground}.</p> * * <p>This method won't be invoked if the task was cancelled.</p> * * @param result The result of the operation computed by {@link #doInBackground}. * * @see #onPreExecute * @see #doInBackground * @see #onCancelled(Object) */ @SuppressWarnings({"UnusedDeclaration"}) @MainThread protectedvoidonPostExecute(Result result){ }
/** * Runs on the UI thread after {@link #publishProgress} is invoked. * The specified values are the values passed to {@link #publishProgress}. * * @param values The values indicating progress. * * @see #publishProgress * @see #doInBackground */ @SuppressWarnings({"UnusedDeclaration"}) @MainThread protectedvoidonProgressUpdate(Progress... values){ }
/** * <p>Runs on the UI thread after {@link #cancel(boolean)} is invoked and * {@link #doInBackground(Object[])} has finished.</p> * * <p>The default implementation simply invokes {@link #onCancelled()} and * ignores the result. If you write your own implementation, do not call * <code>super.onCancelled(result)</code>.</p> * * @param result The result, if any, computed in * {@link #doInBackground(Object[])}, can be null * * @see #cancel(boolean) * @see #isCancelled() */ @SuppressWarnings({"UnusedParameters"}) @MainThread protectedvoidonCancelled(Result result){ onCancelled(); } /** * <p>Applications should preferably override {@link #onCancelled(Object)}. * This method is invoked by the default implementation of * {@link #onCancelled(Object)}.</p> * * <p>Runs on the UI thread after {@link #cancel(boolean)} is invoked and * {@link #doInBackground(Object[])} has finished.</p> * * @see #onCancelled(Object) * @see #cancel(boolean) * @see #isCancelled() */ @MainThread protectedvoidonCancelled(){ }
/** * Returns <tt>true</tt> if this task was cancelled before it completed * normally. If you are calling {@link #cancel(boolean)} on the task, * the value returned by this method should be checked periodically from * {@link #doInBackground(Object[])} to end the task as soon as possible. * * @return <tt>true</tt> if task was cancelled before it completed * * @see #cancel(boolean) */ publicfinalbooleanisCancelled(){ return mCancelled.get(); }
/** * <p>Attempts to cancel execution of this task. This attempt will * fail if the task has already completed, already been cancelled, * or could not be cancelled for some other reason. If successful, * and this task has not started when <tt>cancel</tt> is called, * this task should never run. If the task has already started, * then the <tt>mayInterruptIfRunning</tt> parameter determines * whether the thread executing this task should be interrupted in * an attempt to stop the task.</p> * * <p>Calling this method will result in {@link #onCancelled(Object)} being * invoked on the UI thread after {@link #doInBackground(Object[])} * returns. Calling this method guarantees that {@link #onPostExecute(Object)} * is never invoked. After invoking this method, you should check the * value returned by {@link #isCancelled()} periodically from * {@link #doInBackground(Object[])} to finish the task as early as * possible.</p> * * @param mayInterruptIfRunning <tt>true</tt> if the thread executing this * task should be interrupted; otherwise, in-progress tasks are allowed * to complete. * * @return <tt>false</tt> if the task could not be cancelled, * typically because it has already completed normally; * <tt>true</tt> otherwise * * @see #isCancelled() * @see #onCancelled(Object) */ publicfinalbooleancancel(boolean mayInterruptIfRunning){ mCancelled.set(true); return mFuture.cancel(mayInterruptIfRunning); }
/** * Waits if necessary for the computation to complete, and then * retrieves its result. * * @return The computed result. * * @throws CancellationException If the computation was cancelled. * @throws ExecutionException If the computation threw an exception. * @throws InterruptedException If the current thread was interrupted * while waiting. */ publicfinal Result get()throws InterruptedException, ExecutionException { return mFuture.get(); }
/** * Waits if necessary for at most the given time for the computation * to complete, and then retrieves its result. * * @param timeout Time to wait before cancelling the operation. * @param unit The time unit for the timeout. * * @return The computed result. * * @throws CancellationException If the computation was cancelled. * @throws ExecutionException If the computation threw an exception. * @throws InterruptedException If the current thread was interrupted * while waiting. * @throws TimeoutException If the wait timed out. */ publicfinal Result get(long timeout, TimeUnit unit)throws InterruptedException, ExecutionException, TimeoutException { return mFuture.get(timeout, unit); }
/** * Executes the task with the specified parameters. The task returns * itself (this) so that the caller can keep a reference to it. * * <p>Note: this function schedules the task on a queue for a single background * thread or pool of threads depending on the platform version. When first * introduced, AsyncTasks were executed serially on a single background thread. * Starting with {@link android.os.Build.VERSION_CODES#DONUT}, this was changed * to a pool of threads allowing multiple tasks to operate in parallel. Starting * {@link android.os.Build.VERSION_CODES#HONEYCOMB}, tasks are back to being * executed on a single thread to avoid common application errors caused * by parallel execution. If you truly want parallel execution, you can use * the {@link #executeOnExecutor} version of this method * with {@link #THREAD_POOL_EXECUTOR}; however, see commentary there for warnings * on its use. * * <p>This method must be invoked on the UI thread. * * @param params The parameters of the task. * * @return This instance of AsyncTask. * * @throws IllegalStateException If {@link #getStatus()} returns either * {@link AsyncTask.Status#RUNNING} or {@link AsyncTask.Status#FINISHED}. * * @see #executeOnExecutor(java.util.concurrent.Executor, Object[]) * @see #execute(Runnable) */ @MainThread publicfinal AsyncTask<Params, Progress, Result> execute(Params... params){ return executeOnExecutor(sDefaultExecutor, params); }
/** * Executes the task with the specified parameters. The task returns * itself (this) so that the caller can keep a reference to it. * * <p>This method is typically used with {@link #THREAD_POOL_EXECUTOR} to * allow multiple tasks to run in parallel on a pool of threads managed by * AsyncTask, however you can also use your own {@link Executor} for custom * behavior. * * <p><em>Warning:</em> Allowing multiple tasks to run in parallel from * a thread pool is generally <em>not</em> what one wants, because the order * of their operation is not defined. For example, if these tasks are used * to modify any state in common (such as writing a file due to a button click), * there are no guarantees on the order of the modifications. * Without careful work it is possible in rare cases for the newer version * of the data to be over-written by an older one, leading to obscure data * loss and stability issues. Such changes are best * executed in serial; to guarantee such work is serialized regardless of * platform version you can use this function with {@link #SERIAL_EXECUTOR}. * * <p>This method must be invoked on the UI thread. * * @param exec The executor to use. {@link #THREAD_POOL_EXECUTOR} is available as a * convenient process-wide thread pool for tasks that are loosely coupled. * @param params The parameters of the task. * * @return This instance of AsyncTask. * * @throws IllegalStateException If {@link #getStatus()} returns either * {@link AsyncTask.Status#RUNNING} or {@link AsyncTask.Status#FINISHED}. * * @see #execute(Object[]) */ @MainThread publicfinal AsyncTask<Params, Progress, Result> executeOnExecutor(Executor exec, Params... params){ if (mStatus != Status.PENDING) { switch (mStatus) { case RUNNING: thrownew IllegalStateException("Cannot execute task:" + " the task is already running."); case FINISHED: thrownew IllegalStateException("Cannot execute task:" + " the task has already been executed " + "(a task can be executed only once)"); } }
mStatus = Status.RUNNING;
onPreExecute();
mWorker.mParams = params; exec.execute(mFuture);
returnthis; }
/** * Convenience version of {@link #execute(Object...)} for use with * a simple Runnable object. See {@link #execute(Object[])} for more * information on the order of execution. * * @see #execute(Object[]) * @see #executeOnExecutor(java.util.concurrent.Executor, Object[]) */ @MainThread publicstaticvoidexecute(Runnable runnable){ sDefaultExecutor.execute(runnable); }
/** * This method can be invoked from {@link #doInBackground} to * publish updates on the UI thread while the background computation is * still running. Each call to this method will trigger the execution of * {@link #onProgressUpdate} on the UI thread. * * {@link #onProgressUpdate} will not be called if the task has been * canceled. * * @param values The progress values to update the UI with. * * @see #onProgressUpdate * @see #doInBackground */ @WorkerThread protectedfinalvoidpublishProgress(Progress... values){ if (!isCancelled()) { getHandler().obtainMessage(MESSAGE_POST_PROGRESS, new AsyncTaskResult<Progress>(this, values)).sendToTarget(); } }
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"}) @Override publicvoidhandleMessage(Message msg){ AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj; switch (msg.what) { case MESSAGE_POST_RESULT: // There is only one result result.mTask.finish(result.mData[0]); break; case MESSAGE_POST_PROGRESS: result.mTask.onProgressUpdate(result.mData); break; } } }
publicclassHandlerThreadextendsThread{ int mPriority; int mTid = -1; Looper mLooper;
publicHandlerThread(String name){ super(name); mPriority = Process.THREAD_PRIORITY_DEFAULT; } /** * Constructs a HandlerThread. * @param name * @param priority The priority to run the thread at. The value supplied must be from * {@link android.os.Process} and not from java.lang.Thread. */ publicHandlerThread(String name, int priority){ super(name); mPriority = priority; } /** * Call back method that can be explicitly overridden if needed to execute some * setup before Looper loops. */ protectedvoidonLooperPrepared(){ }
@Override publicvoidrun(){ mTid = Process.myTid(); Looper.prepare(); synchronized (this) { mLooper = Looper.myLooper(); notifyAll(); } Process.setThreadPriority(mPriority); onLooperPrepared(); Looper.loop(); mTid = -1; } /** * This method returns the Looper associated with this thread. If this thread not been started * or for any reason is isAlive() returns false, this method will return null. If this thread * has been started, this method will block until the looper has been initialized. * @return The looper. */ public Looper getLooper(){ if (!isAlive()) { returnnull; } // If the thread has been started, wait until the looper has been created. synchronized (this) { while (isAlive() && mLooper == null) { try { wait(); } catch (InterruptedException e) { } } } return mLooper; }
/** * Quits the handler thread's looper. * <p> * Causes the handler thread's looper to terminate without processing any * more messages in the message queue. * </p><p> * Any attempt to post messages to the queue after the looper is asked to quit will fail. * For example, the {@link Handler#sendMessage(Message)} method will return false. * </p><p class="note"> * Using this method may be unsafe because some messages may not be delivered * before the looper terminates. Consider using {@link #quitSafely} instead to ensure * that all pending work is completed in an orderly manner. * </p> * * @return True if the looper looper has been asked to quit or false if the * thread had not yet started running. * * @see #quitSafely */ publicbooleanquit(){ Looper looper = getLooper(); if (looper != null) { looper.quit(); returntrue; } returnfalse; }
/** * Quits the handler thread's looper safely. * <p> * Causes the handler thread's looper to terminate as soon as all remaining messages * in the message queue that are already due to be delivered have been handled. * Pending delayed messages with due times in the future will not be delivered. * </p><p> * Any attempt to post messages to the queue after the looper is asked to quit will fail. * For example, the {@link Handler#sendMessage(Message)} method will return false. * </p><p> * If the thread has not been started or has finished (that is if * {@link #getLooper} returns null), then false is returned. * Otherwise the looper is asked to quit and true is returned. * </p> * * @return True if the looper looper has been asked to quit or false if the * thread had not yet started running. */ publicbooleanquitSafely(){ Looper looper = getLooper(); if (looper != null) { looper.quitSafely(); returntrue; } returnfalse; }
/** * Returns the identifier of this thread. See Process.myTid(). */ publicintgetThreadId(){ return mTid; } }
/** * Creates an IntentService. Invoked by your subclass's constructor. * * @param name Used to name the worker thread, important only for debugging. */ publicIntentService(String name){ super(); mName = name; }
/** * Sets intent redelivery preferences. Usually called from the constructor * with your preferred semantics. * * <p>If enabled is true, * {@link #onStartCommand(Intent, int, int)} will return * {@link Service#START_REDELIVER_INTENT}, so if this process dies before * {@link #onHandleIntent(Intent)} returns, the process will be restarted * and the intent redelivered. If multiple Intents have been sent, only * the most recent one is guaranteed to be redelivered. * * <p>If enabled is false (the default), * {@link #onStartCommand(Intent, int, int)} will return * {@link Service#START_NOT_STICKY}, and if the process dies, the Intent * dies along with it. */ publicvoidsetIntentRedelivery(boolean enabled){ mRedelivery = enabled; }
@Override publicvoidonCreate(){ // TODO: It would be nice to have an option to hold a partial wakelock // during processing, and to have a static startService(Context, Intent) // method that would launch the service & hand off a wakelock.
/** * You should not override this method for your IntentService. Instead, * override {@link #onHandleIntent}, which the system calls when the IntentService * receives a start request. * @see android.app.Service#onStartCommand */ @Override publicintonStartCommand(@Nullable Intent intent, int flags, int startId){ onStart(intent, startId); return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY; }
/** * Unless you provide binding for your service, you don't need to implement this * method, because the default implementation returns null. * @see android.app.Service#onBind */ @Override @Nullable public IBinder onBind(Intent intent){ returnnull; }
/** * This method is invoked on the worker thread with a request to process. * Only one Intent is processed at a time, but the processing happens on a * worker thread that runs independently from other application logic. * So, if this code takes a long time, it will hold up other requests to * the same IntentService, but it will not hold up anything else. * When all requests have been handled, the IntentService stops itself, * so you should not call {@link #stopSelf}. * * @param intent The value passed to {@link * android.content.Context#startService(Intent)}. * This may be null if the service is being restarted after * its process has gone away; see * {@link android.app.Service#onStartCommand} * for details. */ @WorkerThread protectedabstractvoidonHandleIntent(@Nullable Intent intent); }











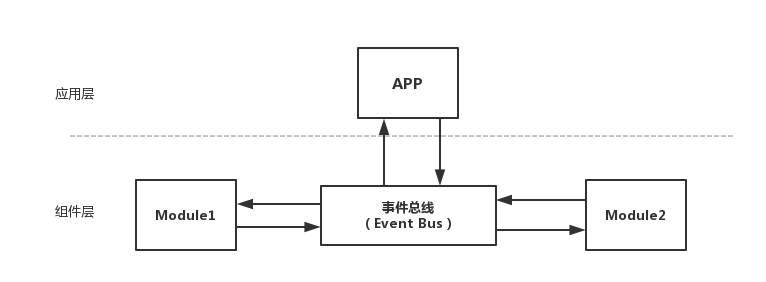

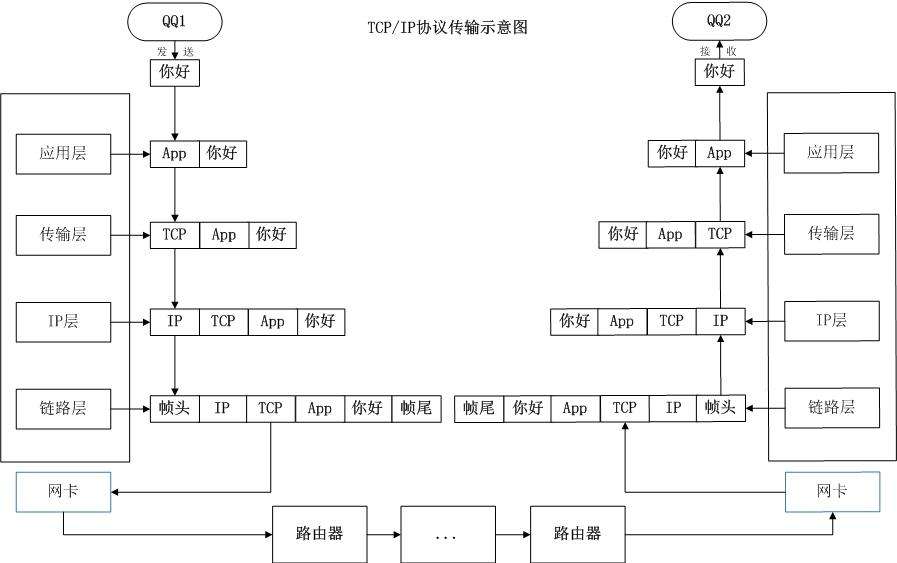


























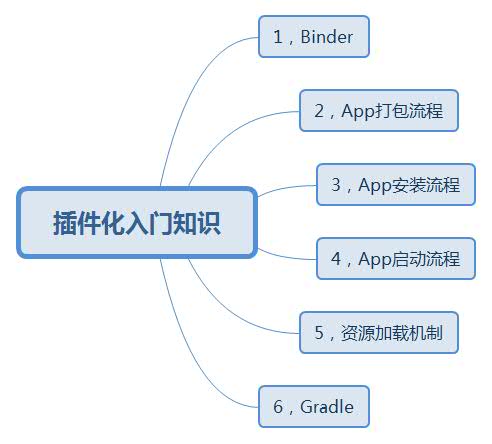

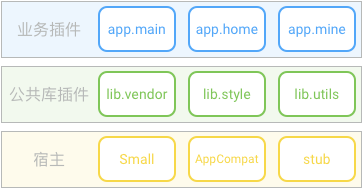
 实现思路:
实现思路: