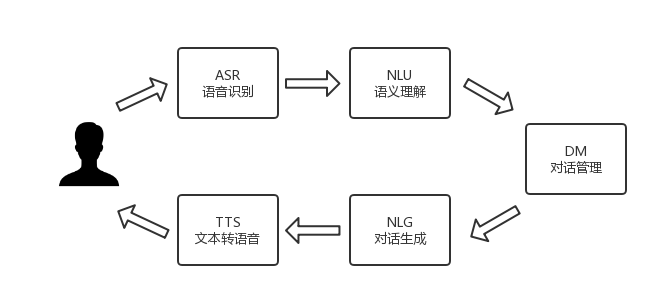
1,发展历程?
ASR: 属于模式识别范畴,它通过某种方式将给定的波形序列转换成相应的字符序列,因此可以理解为模式识别中的分类问题,其中统计建模是目前主流的ASR方法。
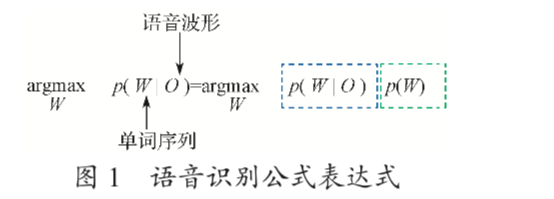
图 1 示出 ASR 公式表达式,建模后针对输入的波形序列 O 用贝叶斯 决策最大后验概率方法估计得到最优输出序列 W。其中, 条件概率 P ( O | W ) 表示模型生成观察序列的概率对应 ASR 系统的声学模型(acoustic model,AM);似然值 P(W) 表示序列 W 出现的一个先验概率,称之为语言模型(language model,LM)[1]。
ASR 系统主要由前端处理、声学模型、语言模型及 解码器 4 个模块组成。解码过程主要是利用训练的声学 模型和语言模型,搜索得到最佳的输出序列
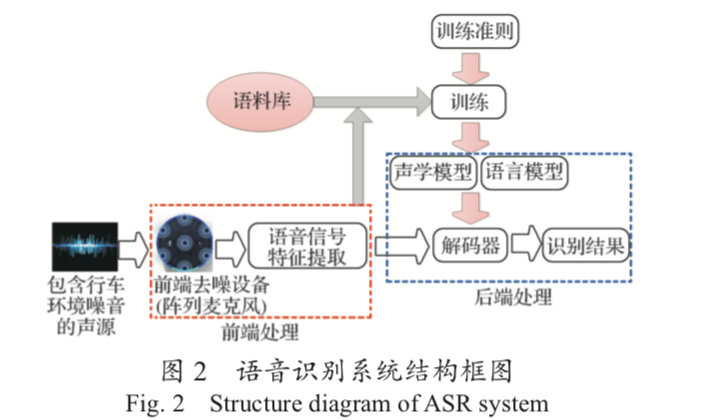
这其中就是声学模型和语言模型显得很关键了。
语音序列经过前端处理提取出语音特征,将该特征作为声学模型的输入。声学模型整合了声学和发声学的知识,将输入的可变长特征序列生成声学模型的分数。
语言模型的输入主要是文本,通过该模型学习文本中词与词之间的关系,估计词序列的可能性。 语言模型是在路径搜索过程中帮助声学模型做出对文本路径更准确的判断。对给定的特征向量序列和若干假设词序列,解码器计算声学模型分数和语言模型分数,并将总体输出分数最高的词序列当作识别结果 。
建立语音识别系统框架后,最重要的是数据的采集及标注。对于不同的语言种类,需要构建不同的语音数据库,依此对模型进行训练,实现不同语言种类的语音识别。
**2,具体算法和原理 **
ASR: 声学模型发展历程
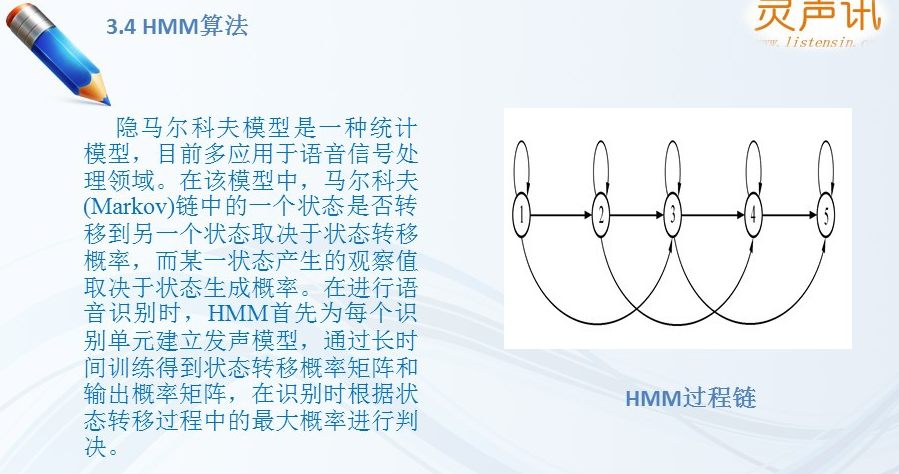
1,20世纪70年代,隐马尔科夫模型( hidden Markov model ),HMM被用以进行声学建模,21世纪初,GMM-HMM(高斯混合分布-隐马尔科夫),虽然前面两个技术显著降低了ASR的错误率,但是还无法达到商用标准。
2,2006年,随着深度学习技术发展,一种深度学置信网络(deep belief network,DBN),指出深度神经网络因为层数 过多而导致训练参数多的问题可以利用逐层初始化方法 来解决,这是深度学习出现的重要标志,此后在工业界 和学术界掀起了深度学习的热潮。
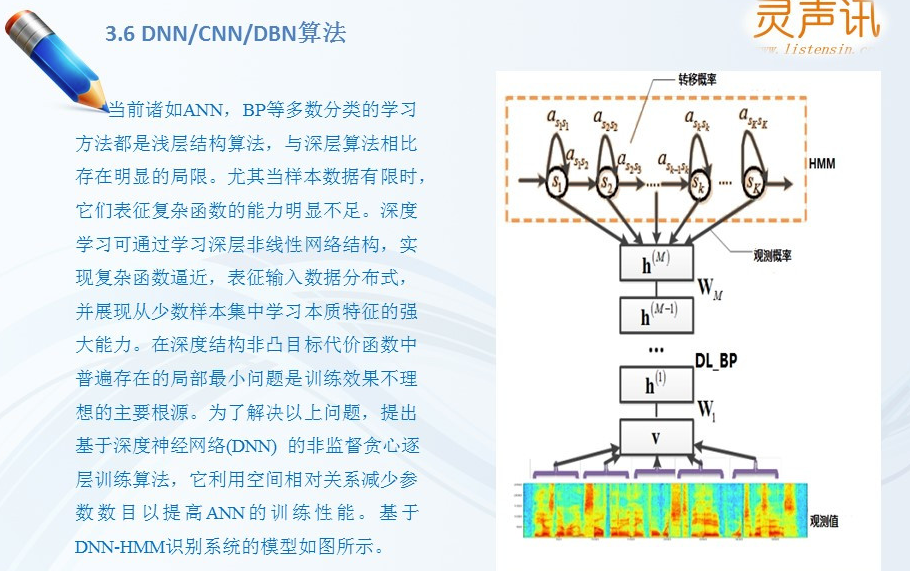
3,深度学习出现之后,首次被应用到ASR中的模型为深度神经网络 - 隐马尔科夫模型(DNN-HMM),深度神经网络(deep neural network,DNN)能利用帧的上下文信息,学习深层非线性特征变换,表现优于 G M M,但是不能利用历史信息来辅助当前任务。
4,卷积神经网络 (convolution neural network,CNN),最开始应用 于图像处理,而后用于 ASR 中的频谱图,它可以克服传统 ASR 中因采用时间、频率而导致的不稳定问题。 DNN 和 CNN 模型均未利用语音之间的关联信息, 而循环神经网络 - 隐马尔科夫模型(RNN-HMM)则充分考虑了语音之间的相互关系,因此取得更好的效果。循环神经网络(recurrent neural network, RNN)能有效利用 历史信息,将历史消息持久化,且在很多任务上,RNN 性能优于 DNN 的,但是 RNN 会随着层数的增加而导致 梯度爆炸或者梯度消失。
5,一个改进的模型是基于长短时记忆单元(long short term memory,LSTM)的递归结构, 相比于普通的 RNN,LSTM 通过精心设计的门结构来控 制信息的存储、输入和输出,同时可以在一定程度上避 免普通 RNN 的梯度消失问题,从而可以有效地对时序信 号的长时相关性进行建模。 此后,大量研究人员将 目光转移到基于 LSTM 的语音声学建模的研究中。
6,作为声学模型,LSTM 通常包含 3~5 个 LSTM 层, 但是直接堆积更多的 LSTM 层来构建更深的网络往往不 会带来性能的提升,反而会由于退化问题使得模型的性 能更差。所以为了进一步优化 LSTM 的结构,Residual- LSTM[14],Highway-LSTM[15] 和 RHN (recurrent highway networks) [16] 方法被提出用于语音声学建模。
7,目前大多数 ASR 系统采用神经网络 - 隐尔科夫模型(NN-HMM)的 混合系统,其需要训练一个声学模型和语言模型,然后 再结合词典进行解码, 关于声学模型,最新的一个热点 是研究端到端的语音识别系统,希望可以去除 HMM, 直接输入声学特征就可以得到识别的词序列,其中具有 代表性的是 CTC(connectionist temporal classification) 模 型和基于 Attention 的 Encoder-decoder 模型。
语音中常用的特征信息:

ASR: 语言模型
1, N-gram 模型是采用较多的语言模型方法, 其中 N 表示该模型在语义上认为相近的几个词是有关联的。 N-gram 模型最大的问题是概率估计得不精准,特别是 N 很大的时候,若要保证精度,则需要的数据量很大, 但是实际上我们不可能获得那么多的训练数据,且参数若很多,数据则会变得稀疏
2,2002 年法国国家科学研究中心 (CNRS) 在电话 ASR 系统中引入了神经网络模型,大幅降低了 识别的错误率。但是基于神经网络的语言模型以词为基 础单元,如果采用全连接网络,上下层之间的词汇量巨 大,计算复杂度高 [19];同时可利用的词语信息比较单一, 没有涉及词性、声调等内容。基于此,Morin 和 Bengio 提出了分层概率神经网络模型(hierarchical probabilistic language model,NNLM)。该模型采用词聚类的方法 计算后验概率,降低了运算复杂度,但是性能并没有得 到提高
3, 2010 年,Mikolov 等人提出一种循环神经网络语言模型(recurrent neural network language model,RNNLM)[21],其通过隐含层循 环利用历史信息,提高了识别性能。针对梯度衰减的问 题,通过 LSTM 或者 GRU(门控循环单元)这种改进 结构来弥补,明显提升了识别性能
4,近年来,语言模型的研究主要向模型优化、解码等 方面展开。模型优化从模型入手,更新模型结构,获取 更好的训练方式
5,2018 年 6 月,阿里巴巴公司达摩院机器智能实验室 开源了新一代 ASR 模型深层前馈序列记忆神经网络(deep feed-forward sequential memory networks,DFSMN),该 模型在最大的 ASR 数据库 LibriSpeech 上的测试准确率 (96.04%)达到了一个新的高度。相比于采用 LSTM 的 模型,该模型优点是训练时间短、准确率高。基于此, 可以构建更多智能语音应用。
语音识别基本框架
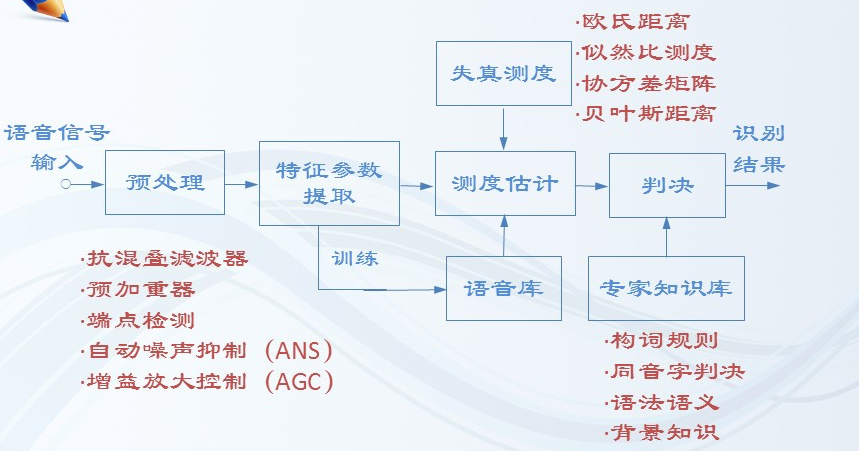
语音识别基本原理

核心技术:

核心算法:
3,车载领域
车载语音平台的需求源于用户所习惯的点击、滑动 等触摸型交互方式在车载环境下存在潜在安全隐患且不 完全好用,语音这一天然适应车载环境的交互方式进而 成为车内一种固定的操作习惯, ASR 是实现语音交互 的关键技术。目前,美国语音技术巨头 Nuance 公司、 中国的科大讯飞股份有限公司(简称“科大讯飞”)、 北京云知声信息技术有限公司(简称“云知声”)、苏 州思必驰信息科技有限公司(简称“思必驰”)及出门 问问公司等均在车载 ASR 领域进行探索和布局。
车载 ASR 技术也伴随着车联网的发 展经历了 3 个阶段:
- 阶段 1,实现了车载语音想象力的简单播报 功能,但只做到了单向输出,并没有实现 ASR 功能。
- 阶段 2,实现了 ASR 功能,但是用户在有干 扰的情景下对语音的识别率较低,无法很好地进行语音 交互。
- 阶段 3,实现了准确、便捷的语音交互功能, 用户能够通过语音系统体验部分服务。
科大讯飞
科大讯飞可以提供包括语音识别、语音合成和声纹 识别等全方位的语音交互平台,是拥有自主知识产权的 智能语音技术公司。2017 年底,该公司发布了汽车智 能交互系统飞鱼 2.0,这是该公司推出的面向车厂定制 的跨平台软件产品。广汽 GS8 型 SUV 汽车搭载了该系 统,通过语音识别实现了空调温度控制、车窗开闭以及 地图导航等智能操作。该系统的优势还包括具有阵列降 噪功能,过滤噪声后,语言识别率更高;同时还具有声 纹识别及回声消除功能。这两种功能可实现司机的身份 认证并消除其他音源对交互的干扰。
百度
百度语音识别为开发者提供业界优质且免费的语音 服务,通过场景识别优化,为车载导航、智能家居和社 交聊天等行业提供语音解决方案。百度 DuerOS 2.0 智 能硬件产品是百度公司推出的一款对话式人工智能操作 系统。自 2017 年起,公司通过该系统拥有超过 130 家 合作伙伴,并快速落地家居、车载、移动等场景,覆盖 手机、电视、OTT 机顶盒、投影、音箱、冰箱、儿童玩具、 智能车机、智能后视镜等众多硬件品类。北汽集团新上 市的微型电动汽车 LITE 上就搭载了 DuerOS 系统。
Bose公司
Bose 公司开发的 ClearVoice 技术是为语音交互系 统服务的。ClearVoice 技术的作用类似阵列降噪,可以 把噪声过滤掉,进而识别出人声指令,保证指令的准确 接收。Bose 公司开发的 SoundTrue 技术,用于车辆座 椅内置扬声器(图 3),可以让不同座位上的人听到不同的音量,从而带来与此前完全不同的音乐效果;甚至还可以通过这样的技术,用音乐来打造一个非常自然的隐私空间,让前座或者后座的人可以自在地交谈。

在轨道交通领域实践
1 | 语音识别是智能人机交互的关键所在。中车株洲电力机车研究所有限公司(简称“中车株洲所”)已实现语音识别技术在轨道交通领域的工程化应用,主要包括以下几个方面功能 |
(1)语音唤醒 (2)命令词识别 (3)声纹识别。用于司机身份认证,使非司乘人 员无法操控列车,达到安全驾驶的目的
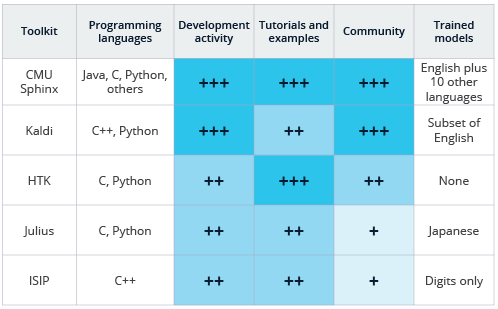
4,常见开源工具包

5,常见开源框架
(1),pytorch-kaldi: https://github.com/mravanelli/pytorch-kaldi

(2),ASRT: https://asrt.ailemon.me
ASRT是一套基于深度学习实现的语音识别系统,全称为Auto Speech Recognition Tool,由AI柠檬博主开发并在GitHub上开源(GPL 3.0协议)。本项目声学模型通过采用卷积神经网络(CNN)和连接性时序分类(CTC)方法,使用大量中文语音数据集进行训练,将声音转录为中文拼音,并通过语言模型,将拼音序列转换为中文文本。算法模型在测试集上已经获得了80%的正确率。基于该模型,在Windows平台上实现了一个基于ASRT的语音识别应用软件,取得了较好应用效果。这个应用软件包含Windows 10 UWP商店应用和Windows 版.Net平台桌面应用,也一起开源在GitHub上了。
(3),WeNet: https://github.com/mobvoi/wenet
The main motivation of WeNet is to close the gap between research and production end-to-end (E2E) speech recognition models, to reduce the effort of productionizing E2E models, and to explore better E2E models for production.
(4),DeepSpeech: https://github.com/PaddlePaddle/DeepSpeech
DeepSpeech on PaddlePaddle是一个采用PaddlePaddle平台的端到端自动语音识别(ASR)引擎的开源项目, 我们的愿景是为语音识别在工业应用和学术研究上,提供易于使用、高效和可扩展的工具,包括训练,推理,测试模块,以及 demo 部署。同时,我们还将发布一些预训练好的英语和普通话模型。
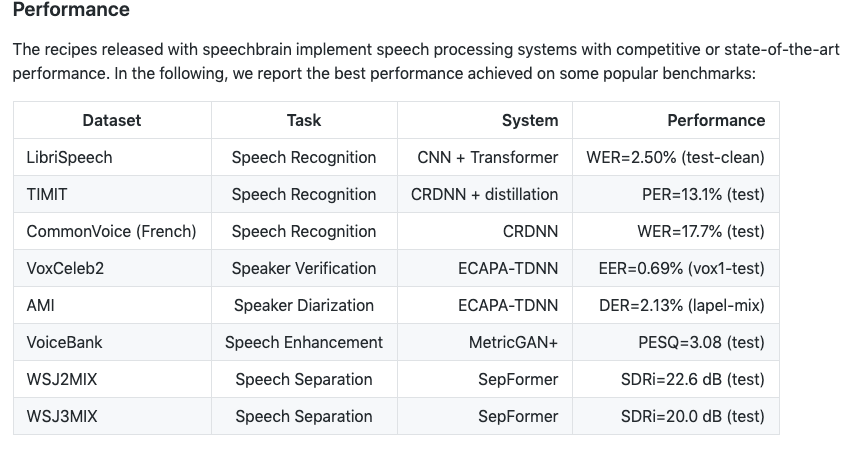
(5),SpeechBrain: https://github.com/speechbrain/speechbrain
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.The goal is to create a single, flexible, and user-friendly toolkit that can be used to easily develop state-of-the-art speech technologies, including systems for speech recognition, speaker recognition, speech enhancement, multi-microphone signal processing and many others.
(6),deepasr: https://www.paddlepaddle.org.cn/modelbasedetail/deepasr
DeepASR 是一个基于 PaddlePaddle Fluid 与 Kaldi 的语音识别系统。其利用 Fluid 框架完成语音识别中声学模型的配置和训练,并集成 Kaldi 的解码器,对 Kaldi 的较为熟悉的用户可以方便的实现声学模型的快速、大规模训练,并利用 Kaldi 完成复杂的语音数据预处理和最终的解码过程。
(7),DeepSpeech2: https://www.paddlepaddle.org.cn/modelbasedetail/DeepSpeech2
一个采用 PaddlePaddle 平台的端到端自动语音识别(ASR)引擎的开源项目,具体原理请参考论文 Deep Speech 2: End-to-End Speech Recognition in English and Mandarin。
6,未来发展方向
ASR模块
(1)多乘客交互。通过采用车内多麦克风分布式布局,实现主驾驶、副驾驶、中排两侧、后排两侧均能够采集司机及乘客语音,并且当车内多个人同时进行语音交互时,车载语音识别系统能够区分不同声音,分别对不同声源做出相应的反馈,互不干扰。
(2)情感化交互。情感化交互是指机器能够带有情感地与人进行语音 交互,涉及语音识别、语音合成和语义理解 3 个方面。 语音合成方面,已经有多种类型仿真人声的技术,若想 将其做得更好,则需发展语义理解技术,而这是最复杂的技术。
研究方向
1,麦克风阵列
麦克风阵列是近几年广泛应用于语音领域的拾音设 备,主要解决远距离语音识别的问题,以保证真实场景 下的语音识别率。 麦克风阵列由一组按一定几何结构(通 常为线形和环形)摆放的麦克风组成(图 8),对所采 集的不同空间方向的声音信号进行空时处理,实现噪声 抑制、混响去除、人声干扰抑制、声源测向、声源跟踪 和阵列增益等功能,以提高语音信号处理质量,进而提 高真实环境下的语音识别率。

麦克风阵列只是完成了物理世界的声音信号处理,需要与后端软件系统相匹配才能得到最好的效果。为提高语音识别的准确率,语音降噪是必须采用的关键技术。
当前较成熟的麦克风阵列主要包括:科大讯飞的 2 麦、4 麦和 6 麦方案,思必驰的 6(+1)麦方案,云知声 的2麦方案,以及北京声智科技有限公司的2麦阵列、(4 +1) 麦阵列、6(+1)麦阵列和 8(+1)麦阵列方案。具体而言,是采用环形阵列还是线形阵列,以及采用几麦方案, 这都需要根据不同应用场景的音频测试结果来决定。
7,参考资料
1,https://www.kdnuggets.com/2017/03/open-source-toolkits-speech-recognition.html
2,https://en.wikipedia.org/wiki/List_of_speech_recognition_software